An ebuild Testing Solution for ebuild Repositories
Common package managers implement the concept of software repositories to
allow the set of packages installable from the package manager to be expanded.
On Fedora, there is RPM Fusion and Copr repositories created and maintained by
users. Arch Linux users are fond of the AUR, the canonical repository for
user-submitted packages. On Gentoo, there is GURU, which is kind of like
Gentoo’s equivalent of AUR, but it is just the tip of the iceberg of packages
that are not in the official Gentoo ebuild repository (::gentoo). There are
various testing overlays maintained by projects and development teams of Gentoo
and repositories for out-of-tree ebuilds, like ::gnome, ::java, and
::science, let alone plenty of user personal overlays, like the Spark
overlay I have been working on for example.
As covered in my previous blog article, when there are
packages, there exist dependency relationships. Out-of-tree packages in an
external repository may depend on packages in not only the same repository but
also the main repository for the GNU/Linux distribution too because there is no
reason to reinvent the wheel if any existing packages suffice for the
dependency requirements. For example, packages in the Spark overlay, which are
mostly Java packages, depend on some Java libraries packaged in ::gentoo such
as dev-java/ant-core, dev-java/gson and dev-java/commons-lang. An extra
benefit of reusing existing packages for dependencies for users is that if
users have already installed those packages, they do not need to install it
again or install another copy, saving both time and disk space.
We are in a universe that is changing every second, and so does ::gentoo.
For an average day, the pulse for ::gentoo on GitHub
suggests that hundreds of commits are merged into it, and some of these commits
would remove outdated versions of a package or even an entire obsolete package.
If any external ebuild repositories depend on those removed versions or the
removed package, then the ebuilds in them will no longer be installable due to
the broken dependency graph caused by the removal. This is exactly what
happened to the Spark overlay: after the final release of the overlay for last
year’s GSoC, many Java dependencies of ebuilds in it that had been provided by
::gentoo were cleaned up earlier this year.
After less than two weeks of work, I have resolved all missing dependencies and
restored ebuilds in the Spark overlay back to a working state. But I promise
that more dependencies required by Spark overlay ebuilds will be removed from
::gentoo in the future, and that is when further maintenance will be
required. How can I and any other maintainers of the Spark overlay be aware of
such issues when they arise? Reinstalling every package in the Spark overlay
with the latest copy of ::gentoo every day on our own computers could help
detect this kind of problems, but this would not be a realistic solution.
It would be great if there could a dedicated infrastructure that downloads the
latest copies of ::gentoo and the Spark overlay to a Gentoo system, tests the
Spark overlay ebuilds by installing them onto the system, and reports any
installation issues to the maintainers automatically every day. This led me
into contemplating leveraging continuous integration (CI) for ebuild
installation testing because a CI service is not only capable of doing those
types of tasks but also designed for that purpose inherently. In this article,
I will present the solution I have deployed to the Spark overlay and have been
using during the past two weeks for automated ebuild testing: CI builds within
GitHub Actions that conduct installation tests on Spark overlay ebuilds inside
a Docker container based on the Gentoo stage3 image,
which acts like a minimal Gentoo system image.
Requirements for the Testing Solution
Since I would use the testing solution I was creating myself, I thought about some properties of the ebuild testing solution that I would like to see by reflecting how I tested the ebuilds for Kotlin core libraries from source and also considered any useful features for any other developers who might want to use it under a different workflow.
The first definite requirement I had was that it must support running a
sequence of emerge commands in a single environment for testing. This was
stemmed from the fact that the current version of my Kotlin ebuilds require
more than a single emerge command for installation. This
ruled out the possibility of using ebuildtester, an existing
Docker-based Gentoo package testing utility, because it does not have an
interface for running multiple emerge commands in sequence.
Next, I would like to use a custom set of Portage configuration files (files
under ${PORTAGE_CONFIGROOT}/etc/portage) for the tests. For some critical
ebuilds, I would like to not only install them but also run their tests by
enabling FEATURES="test" for those specific ebuilds. I did not want to set
FEATURES="test" for all ebuilds because there would be no need to run tests
for dependency packages from ::gentoo, and turning them off could also reduce
the overall test runtime. To achieve this, the most straightforward way is to
use /etc/portage/package.env and /etc/portage/env to enable tests only for
select packages, hence the ability to use a custom set of Portage configuration
files is needed.
# /etc/portage/env/features-test.conf
FEATURES="test"# /etc/portage/package.env
# Enable tests for ebuilds in the Spark overlay only
*/*::spark-overlay features-test.confIn addition, any programs used for the tests should be runnable both in a CI environment and on any maintainer’s personal computer, and the behaviors of tests should be consistent everywhere. In the event where an error has occurred in a CI build, this would allow the maintainers to inspect the error locally. As long as the testing solution does not use too many obscure tools, and the tests can be triggered with only a few commands, this requirement is easy to meet.
Last but not least, any ebuild installation tests should be done in an isolated environment rather than directly on the host where the tests are being run. This both avoids messing up maintainers’ systems and prevents instances of It Works for Me™ – for example, an ebuild requires a dependency that exists on a maintainer’s system but is not declared in the ebuild, blocking users who do not have the dependency on their system from successfully installing the ebuild.
ebuild-commander: Run Commands in Docker Container for ebuild Tests
Although ebuildtester could not meet some of the requirements, I appreciated its testing approach: it would create a new environment derived from Gentoo stage3 and install the package requested to be tested in it, and the environment is a Docker container. ebuildtester is like a wrapper of Docker specialized for operations relevant to ebuild installation, and it interacts with Docker via its command-line interface.
Docker is available in both GitHub Actions runners and ::gentoo, and it
inherently isolates the file system of any containers used for testing from the
host system, so the last two requirements listed in the previous section can be
satisfied. For the first two requirements, docker exec can be used to run a
command inside a container, and Docker’s bind mount feature (controlled by
the --mount and -v flags of some Docker subcommands) is useful for
importing a custom Portage configuration directory to the container’s
/etc/portage. Inspired by the fact that ebuildtester just calls various
docker commands to test installation of an ebuild, I decided to imitate
ebuildtester’s implementation and write my own Docker wrapper that supports
running multiple commands in a container, by making a batch of docker exec
invocations and bind mounting a directory’s contents to /etc/portage.
After stealing lots of code from ebuildtester and adding my augmentations, a
program that mimics ebuildtester but accepts a list of commands as input
instead of a package atom was created, and I named it
ebuild-commander for the fact that it enables users to run
any set of commands – not just emerge – in a container used for ebuild
testing. The commands list can be stored in a file or passed in via standard
input, which both allows the commands to be piped in from another program and
enables users to run commands in a Docker container in a pseudo-interactive
way.
For Portage configuration directory imports, I first trivially implemented the
feature by binding the directory containing the configuration specified in the
arguments to ebuild-commander to /etc/portage in the container. But later
on, when more test cases using varied Portage configurations were being added,
I found that the configuration directory was mostly the same for every test
case and had exclusive settings in only a few files. To encourage
configuration file reuse, I added layered configuration
support to ebuild-commander so it could take
multiple configuration directories from the command-line arguments to it, use
the first directory as the base configuration, and copy contents in subsequent
directories into the base one in order.
For example, if maintainers would like to run a 2-dimensional matrix of tests
defined in the following table, they can create a base configuration default
and a configuration override for each dimension. Then, they can call
ebuild-commander with 2² = 4 different combinations of configuration
directories for the test case matrix.
| Configurations used | USE="-binary" |
USE="binary" |
|---|---|---|
FEATURES="-test" |
default |
default, binary |
FEATURES="test" |
default, features-test |
default, binary, features-test |
./
├── binary
│ └── package.use
│ └── binary
├── default
│ ├── make.conf
│ └── package.use
│ ├── for-hadoop-common
│ ├── for-openjfx
│ └── scala
└── features-test
├── env
│ └── features-test.conf
└── package.env
└── features-test$ ebuild-cmder --portage-config default
$ ebuild-cmder --portage-config default --portage-config features-test
$ ebuild-cmder --portage-config default --portage-config binary
$ ebuild-cmder --portage-config default --portage-config binary --portage-config features-test
Test Scripts and Test Case Definitions: Inspired by the Format of ebuilds
As demonstrated above, ebuild-commander invocation commands might get very long if many Portage configuration directories are being used, so it would be better to put them into scripts. Because I was working on ebuild creation and maintenance when this testing solution was being developed, design of the scripts that run the test cases with ebuild-commander was largely influenced by the mechanisms of ebuilds.
An ebuild is essentially a Bash-compatible script file. When it is being
installed by a Gentoo package manager like Portage, it is sourced to set
variables, such as SRC_URI, SLOT and DEPEND, and define functions, like
src_compile and src_install. Then, the package manager will call the phase
functions declared in the Gentoo Package Manager Specification in
order. When an ebuild inherits an eclass, the eclass is
sourced in a similar way and can access any variables defined by the ebuild
before the inherit statement. source, a plain Bash shell built-in, has the
potential to support a sophisticated and powerful system package manager for a
GNU/Linux distribution.
Based on the idea of leveraging source, I created a test entry point script
that would source each test case given in the arguments to it, build
command-line arguments to ebuild-commander according to the variables set in
the test case script, and pass commands listed in the run_test function of
the test case script to ebuild-commander via standard input.
#!/usr/bin/env bash
DEFAULT_EMERGE_OPTS="--color y --verbose --keep-going"
if [[ -z "$@" ]]; then
echo "Usage: $0 TESTCASE..."
exit 1
fi
for script in "$@"; do
# Reset the environment
unset EMERGE_OPTS DOCKER_IMAGE PROFILE GENTOO_REPO THREADS PULL
unset STORAGE_OPTS SKIP_CLEANUP PORTAGE_CONFIGS CUSTOM_REPOS
source "${script}"
args=(
ebuild-cmder
--portage-config tests/portage-configs/default
--custom-repo .
--emerge-opts "${EMERGE_OPTS:-"${DEFAULT_EMERGE_OPTS}"}"
${DOCKER_IMAGE:+--docker-image ${DOCKER_IMAGE}}
${PROFILE:+--profile ${PROFILE}}
${GENTOO_REPO:+--gentoo-repo ${GENTOO_REPO}}
${THREADS:+--threads ${THREADS}}
${PULL:+--pull}
${STORAGE_OPTS:+--storage-opts ${STORAGE_OPTS}}
${SKIP_CLEANUP:+--skip-cleanup ${SKIP_CLEANUP}}
)
for config in "${PORTAGE_CONFIGS[@]}"; do
args+=( --portage-config "${config}" )
done
for repo in "${CUSTOM_REPOS[@]}"; do
args+=( --custom-repo "${repo}" )
done
# Pipe the run_test function's body into ebuild-commander
type run_test | sed '1,3d;$d' | "${args[@]}"
doneA test case could then be defined like this, which is kind of like a mini
ebuild with a run_test “phase function”:
# A installation test case for Kotlin packages
PORTAGE_CONFIGS=( tests/portage-configs/kotlin )
run_test() {
# Library bootstrap stage 1
USE="binary" emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect
emerge dev-lang/kotlin-bin
# Library bootstrap stage 2
emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect
# Library bootstrap stage 3
find /var/db/repos/spark-overlay -type d -name 'kotlin-core-*' \
-printf '%P\0' | xargs -0 emerge -1 \
dev-java/kotlin-stdlib{,-js} dev-java/kotlin-reflect
# Test additional packages
emerge -1 dev-java/kotlin-test-js
emerge dev-java/kotlin-stdlib-jdk8
FEATURES="test" emerge -1 \
dev-java/kotlin-stdlib{,-jdk7,-jdk8} \
dev-java/kotlin-test{,-junit}
}The PORTAGE_CONFIGS variable would be set in the environment after the test
script is sourced by the entry point script, and the entry point script could
use its value to add --portage-config options to the arguments to
ebuild-commander accordingly. Other variables controlling arguments to
ebuild-commander would work in the same way as well.
Finally, type run_test | sed '1,3d;$d' would be used to preprocess the
contents of the run_test function for reformatting, white space removal, etc.
and to make sure they are ready to be piped into ebuild-commander. This is a
Bash trick for obtaining the body of a function. Assuming run_test has been
defined as a function, type run_test prints a description of it and its body
with curly braces, and sed '1,3d;$d strips the first three lines plus the
last line from the input to it.
$ type run_test
run_test is a function
run_test ()
{
USE="binary" emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect;
emerge dev-lang/kotlin-bin;
emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect;
find /var/db/repos/spark-overlay -type d -name 'kotlin-core-*' -printf '%P\0' | xargs -0 emerge -1 dev-java/kotlin-stdlib{,-js} dev-java/kotlin-reflect;
emerge -1 dev-java/kotlin-test-js;
emerge dev-java/kotlin-stdlib-jdk8;
FEATURES="test" emerge -1 dev-java/kotlin-stdlib{,-jdk7,-jdk8} dev-java/kotlin-test{,-junit}
}
$ type run_test | sed '1,3d;$d'
USE="binary" emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect;
emerge dev-lang/kotlin-bin;
emerge -1 dev-java/kotlin-stdlib dev-java/kotlin-reflect;
find /var/db/repos/spark-overlay -type d -name 'kotlin-core-*' -printf '%P\0' | xargs -0 emerge -1 dev-java/kotlin-stdlib{,-js} dev-java/kotlin-reflect;
emerge -1 dev-java/kotlin-test-js;
emerge dev-java/kotlin-stdlib-jdk8;
FEATURES="test" emerge -1 dev-java/kotlin-stdlib{,-jdk7,-jdk8} dev-java/kotlin-test{,-junit}If there are multiple test cases with a common run_test that differ only in
options like PROFILE and PORTAGE_CONFIGS, then the common parts can go into
a dedicated file, and all test cases can just source this file to include
them. This mechanism is similar to inherit in ebuilds.
# tests/resources/leaf-ebuilds/test-case-tmpl.sh
EMERGE_OPTS="${DEFAULT_EMERGE_OPTS} --quiet-build"
run_test() {
# Update pre-installed packages with required USE flags and versions
emerge -1 dev-java/jsr305
# Install Kotlin 1.4
USE="binary" emerge -1 dev-java/kotlin-{stdlib,reflect}:1.4
emerge -1 dev-lang/kotlin-bin:1.4
/var/db/repos/spark-overlay/tests/resources/leaf-ebuilds/emerge-leaves.sh
}# Test case: USE="binary", FEATURES="-test"
PORTAGE_CONFIGS=( tests/portage-configs/binary )
source tests/resources/leaf-ebuilds/test-case-tmpl.sh# Test case: USE="binary", FEATURES="test"
PORTAGE_CONFIGS=(
tests/portage-configs/binary
tests/portage-configs/features-test
)
source tests/resources/leaf-ebuilds/test-case-tmpl.shNote that at the end of the run_test function for these test cases is a call
to a script located at tests/resources/leaf-ebuilds/emerge-leaves.sh under
/var/db/repos/spark-overlay. /var/db/repos/spark-overlay is the mount
point of the Spark overlay chosen by ebuild-commander, and any arbitrary script
inside the Spark overlay Git repository can be run similarly by appending the
script’s path relative to the repository’s root to the mount point. The
emerge-leaves.sh script calls a Python program that computes
the set of leaf ebuilds in the Spark overlay, whose implementation is described
in my previous post, then installs each leaf ebuild with
emerge. Hence, these test cases can cover every package in the repository.
However, they do not necessarily cover every ebuild: in case a package has
multiple versions that share the same slot, it is possible that only the latest
version in the slot is tested.
GitHub Actions: Test Case Execution and Error Reporting
Now that the test scripts which build and invoke ebuild-commander commands are in place, they are ready to run on both maintainers’ development environment and GitHub Actions, which means a GitHub Actions workflow can be set up to automate test execution. The test scripts can be executed on GitHub Actions in the same way as how someone would start them on their own computer, but there are additional things to consider for GitHub Actions.
The major issue is prolonged test runtime. The GitHub Actions runners hosted
by GitHub are not beefy: the ubuntu-latest runners are equipped with only 2
CPU cores. This is bad news especially for people
working on Gentoo packages because the packages usually need to be compiled
from source, hence this process sets very high demand on the test runner’s
performance. There is also a 6-hour job execution time
limit on those runners. It is possible to use
self-hosted GitHub Actions runners with better hardware, but not everyone can
afford this.
The 6-hour job duration limit would have meant that if the time taken to run through all test cases on a GitHub-hosted runner might be longer than this, then the tests could not complete. However, test execution can be parallelized by using multiple workflow jobs: each job only runs a single test case, and all test cases can thus be run concurrently. This relaxes the test runtime limit so that as long as no single test case needs more than 6 hours to run, the tests would work fine.
To run multiple jobs together, job configurations matrix can be used to define jobs that consist of the same steps with differences only in some parameters. The following snippet shows how I defined two build matrices for two kinds of test cases. I must confess that lots of duplicate code exists in the build matrix definitions since the second matrix has only one additional step the first matrix does not need; however, I still decided to define them separately because they are inherently two different types of test cases which might be changed to be run differently in the future.
jobs:
test-cases:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
test-case:
- spark
- kotlin-latest
- kotlin-1.4
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
with:
python-version: 3.9
- uses: ./.github/actions/run-test-case
with:
path: ./tests/test-cases/${{ matrix.test-case }}.sh
- name: Export ebuild logs if test case failed
if: ${{ failure() }}
run: |
(docker exec $(docker ps -lq) tar -cJvf - /var/log/emerge || true) \
> emerge.tar.xz; [[ -s emerge.tar.xz ]] || rm emerge.tar.xz
- uses: actions/upload-artifact@v2
if: ${{ failure() }}
with:
name: ${{ matrix.test-case }}-ebuild-logs
path: emerge.tar.xz
leaf-ebuilds:
runs-on: ubuntu-latest
continue-on-error: ${{ matrix.may-fail }}
strategy:
fail-fast: false
matrix:
may-fail: [true]
test-case:
- leaf-ebuilds
- leaf-ebuilds-test
- leaf-ebuilds-binary-test
include:
- may-fail: false
test-case: leaf-ebuilds-binary
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
with:
python-version: 3.9
- uses: ./.github/actions/setup-leaf-ebuilds-job
- uses: ./.github/actions/run-test-case
with:
path: ./tests/test-cases/${{ matrix.test-case }}.sh
- name: Export ebuild logs if test case failed
if: ${{ failure() }}
run: |
(docker exec $(docker ps -lq) tar -cJvf - /var/log/emerge || true) \
> emerge.tar.xz; [[ -s emerge.tar.xz ]] || rm emerge.tar.xz
- uses: actions/upload-artifact@v2
if: ${{ failure() }}
with:
name: ${{ matrix.test-case }}-ebuild-logs
path: emerge.tar.xzFor both build matrices, there is a fail-fast: false setting which prevents
all jobs in a matrix from being cancelled after a job in the matrix fails.
Even if a single job has failed, whether or not other jobs in the same matrix
can pass would still be valuable to know, so maintainers can wait for all jobs
to complete, fix all issues, and test the changes together in a single new
GitHub Actions workflow run, instead of fix the single issue, push the change,
trigger another workflow run, find another error in a different job, etc.
For the leaf-ebuilds matrix, an continue-on-error setting is added, and its
value is extracted from the may-fail parameter for each job in the matrix.
This option controls whether or not the entire workflow should be declared to
be a failed one when the job fails, and its purpose is to allow maintainers to
ignore failures of a test case that is known to be unstable or failing. To be
honest, every test case is supposed to pass, and it would be better to
completely disable failing tests completely. Unfortunately, I would not have
had enough time left for the remaining parts of my GSoC project if I had
decided to continue working on the existing ebuilds in the Spark overlay to let
all test cases pass, so I configured them this way in the hope to get a
maintainer to fix the issues and pass the tests in the future.
Next, there are uses of some custom actions, i.e.
those whose names start with ./.github/actions. These can be regarded as
custom functions for GitHub Actions. For example, the run-test-case action
is like a function that sets up ebuild-commander and related files before it
calls the test entry point script to run the specified test case, and it looks
like this:
name: "Run a test case"
description: "Run a test case in a Docker image via ebuild-commander"
inputs:
path:
description: "Path to the test case definition file"
required: true
runs:
using: "composite"
steps:
- name: "Download ebuild-commander"
run: git clone https://github.com/Leo3418/ebuild-commander.git
shell: bash
- name: "Install ebuild-commander"
run: ./setup.py install --user
shell: bash
working-directory: ebuild-commander
- name: "Create directories for ::gentoo and Portage"
run: sudo mkdir -p /var/db/repos/gentoo /etc/portage
shell: bash
- name: "Download ::gentoo"
run: wget -qO - "https://github.com/gentoo-mirror/gentoo/archive/master.tar.gz" | sudo tar xz -C /var/db/repos/gentoo --strip-components=1
shell: bash
- name: "Run the test case"
run: tests/run.sh ${{ inputs.path }}
shell: bashFinally, there are two additional steps after the run-test-case action for
each matrix. These steps are responsible for gathering the Portage ebuild logs
and uploading a tarball containing them as an artifact
for maintainers to peruse in case the test fails (detected using if: ${{ failure() }}). Note that /var/log/emerge is not the default path for ebuild
logs; it is set by adding PORTAGE_LOGDIR="/var/log/emerge" to
/etc/portage/make.conf.
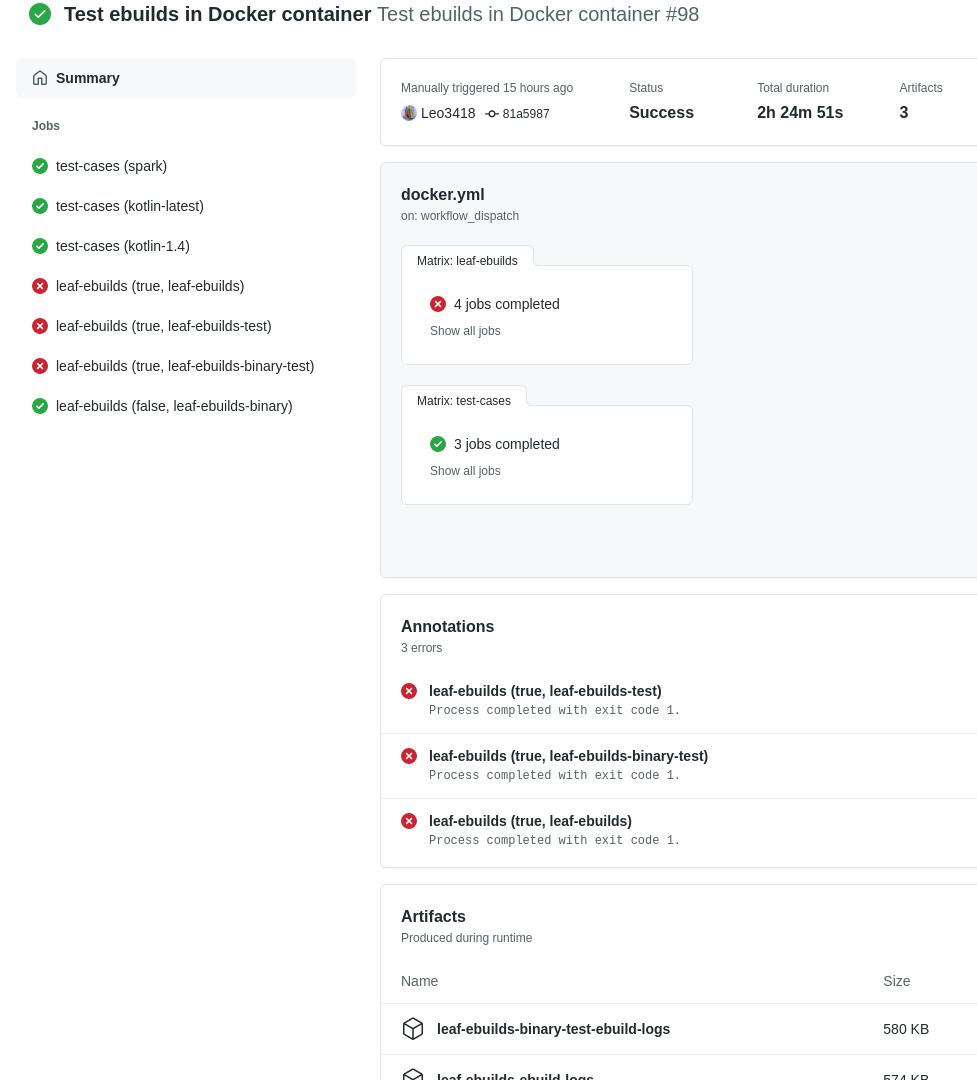
Below is a screenshot of a workflow run based on the above configuration. The
jobs with may-fail: true failed, but the workflow run’s overall status is
still “Success”. For each failed job, an archive of its ebuild logs is
available under “Artifacts”.
While a CI build is usually triggered by a new push to the Git repository, on
GitHub Actions, they can also be configured to run on a
schedule. For ebuild tests, it might be useful to run
them every day, so after a change in ::gentoo has rendered an ebuild in the
repository not installable, the maintainers can be notified of the breakage
within 24 hours.
on:
schedule:
- cron: '0 0 * * *'Use Cases of the Final Solution
I have been using this ebuild testing framework in my fork of the Spark overlay
for more than three weeks, and the tests being run by it have been acting as
both installation tests for the ebuilds in the repository themselves and
integration tests with packages from ::gentoo. If an ebuild’s installation
process cannot complete, emerge will throw a build error; if a dependency in
::gentoo no longer exists, emerge will exit with failure immediately during
the dependency calculation stage. Both kinds of errors are propagated through
Docker, ebuild-commander, the test scripts, and finally to the GitHub Actions
runner, which will eventually draw maintainers’ attention to the underlying
issue. Therefore, for maintainers of external and custom ebuild repositories
who would like to get notified as soon as a change in ::gentoo breaking any
ebuilds in it has happened, this solution can help them achieve the purpose.
Although this solution does not seem to be scalable at all to test the entirety
of ::gentoo, which consists of nearly 20,000 packages as of now, maintainers
who mainly work on ebuilds in ::gentoo can still use this solution for
testing just a small subset of it. For example, developers making changes to a
certain package can use this framework to test the changed ebuild itself as
well as the package’s reverse dependencies. This was exactly how some of the
testing for the new dev-java/jansi-1.13 ebuild I submitted to
::gentoo was done. Another potential use case is that Gentoo
developers can create test cases for the packages they maintain and run them
periodically to capture any issues in them even before any bug report comes in,
so they can fix the problems as soon as possible.